8.5 KiB
Concepts
Concepts
The Fluence solution enables a new class of decentralized Web3 solutions providing technical, security and business benefits otherwise not available. In order for solution architects and developers to realize these benefits, a shift in philosophy and implementation is required. With the Fluence tool chain available, developers should find it possible to code meaningful Web3 solutions in short order once an understanding of the core concepts and Aqua is in place.
The remainder of this section introduces the core concepts underlying the Fluence solution.
Particles
Particles are Fluence's secure distributed state medium, i.e., conflict free replication data structures containing application data, workflow scripts and some metadata, that traverse programmatically specified routes in a highly secure manner. That is, particles hop from distributed compute service to distributed compute service across the peer-to-peer network as specified by the application workflow updating along the way.
Figure 4: Node-Service Perspective Of Particle Workflow

Not surprisingly, particles are an integral part of the Fluence protocol and stack. It is the very decoupling of data + workflow instructions from the service and network components that allows the secure composition of applications from services distributed across a permissionless peer-to-peer network.
While the application state change resulting from passing a particle "through" a service with respect of the data components is quite obvious, the ensuing state change with respect to the workflow also needs to be recognized, which is handled by the Aqua VM.
As depicted in Figure 4, a particle traverses to a destination node's Aqua VM where the next execution step is evaluated and, if specified, triggered. That is, the service programmatically specified to operate on the particle's data is called from the Aqua VM, the particle's data and workflow (step) are updated and the Aqua VM routes the particle to the next specified destination, which may be on the same, another or the client peer.
Aqua
An integral enabler of the Fluence solution is Aqua, an open source language purpose-built to enable developers to ergonomically program distributed networks and applications by composition. Aqua scripts compile to an intermediary representation, called AIR, which execute on the Aqua Virtual Machine, Aqua VM, itself a Wasm module hosted on the Marine interpreter on every peer node.
Figure 5: From Aqua Script To Particle Execution

Currently, compiled Aqua scripts can be executed from Typescript clients based on Fluence SDK. For more information about Aqua, see the Aqua book.
Marine
Marine is Fluence's generalized Wasm runtime executing Wasm Interface Type (IT) modules with Aqua VM compatible interfaces on each peer. Let's unpack.
Services behave similarly to microservices: They are created on nodes and served by the Marine VM and can only be called by Aqua VM. They also are passive in that they can accept incoming calls but can't initiate an outgoing request without being called.
Services are
- comprised of Wasm IT modules that can be composed into applications
- developed in Rust for a wasm32-wasi compile target
- deployed on one or more nodes
- running on the Marine VM which is deployed to every node
Figure 6: Stylized Execution Flow On Peer

Please note that the Aqua VM is itself a Wasm module running on the Marine VM.
The Marine Rust SDK abstracts the Wasm IT implementation detail behind a handy macro that allows developers to easily create Marine VM compatible Wasm modules. In the example below, applying the marine macro turns a basic Rust function into a Wasm IT compatible function and enforces the types requirements at the compiler level.
#[marine]
pub fn greeting(name: String) -> String {
format!("Hi, {}", name)
}
Services
Services are logical constructs instantiated from Wasm modules that contain some business logic and configuration data. That is, services are created, i.e., linked, at the Marine VM runtime level from uploaded Wasm modules and the relevant metadata
Blueprints are json documents that provide the necessary information to build a service from the associated Wasm modules.
Figure 7: Service Composition and Execution Model
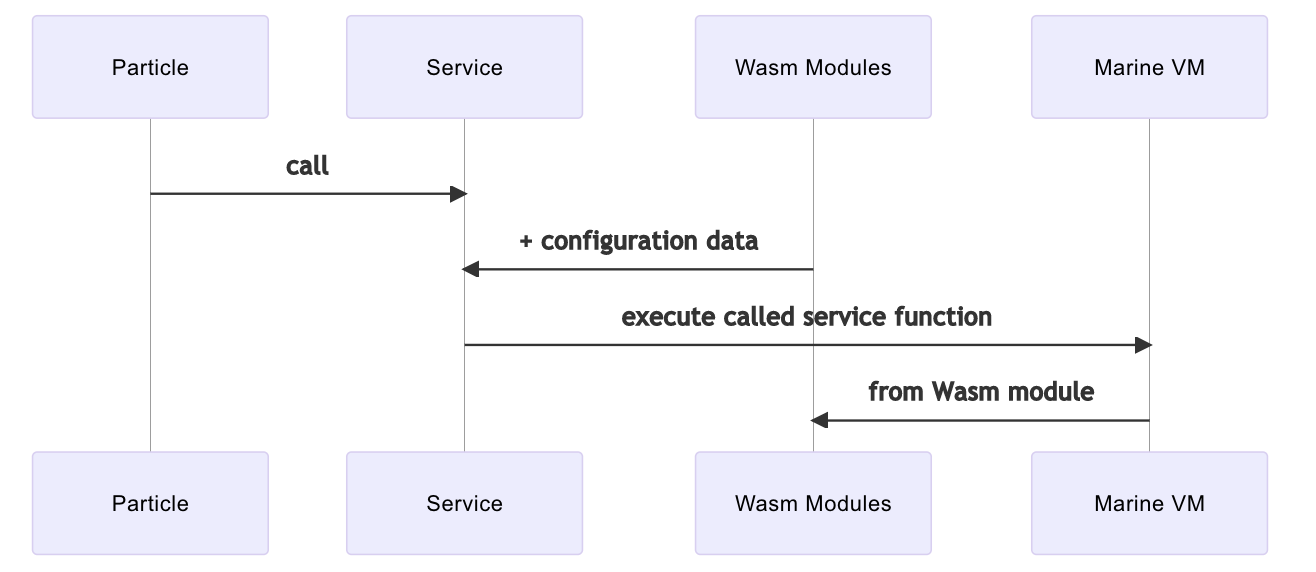
Please note that services are not capable to accept more than one request at any given time. Consider a service, FooBar, comprised of two functions, foo() and bar() where foo is a longer running function.
-- Stylized FooBar service with two functions
-- foo() and bar()
-- foo is long-running
--- if foo is called before bar, bar is blocked
service FooBar("service-id"):
bar() -> string
foo() -> string --< long running function
func foobar(node:string, service_id:string, func_name:string) -> string:
res: *string
on node:
BlockedService service_id
if func_name == "foo":
res <- BlockedService.foo()
else:
res <- BlockedService.bar()
<- res!
As long as foo() is running, the entire FooBar service, including bar(), is blocked. This has implications with respect to both service granularity and redundancy.
Modules
In the Fluence solution, Wasm IT modules take one of three forms:
- Facade Module: expose the API of the service comprised of one or more modules. Every service has exactly one facade module
- Pure Module: perform computations without side-effects
- Effector Module: perform at least one computation with a side-effect
It is important for architects and developers to be aware of their module and services construction with respect to state changes.
Authentication And Permissioning
Authentication at the service API level is an inherent feature of the Fluence solution. This fine-grained approach essentially provides ambient authority out of the box.
In the Fluence solution, this is accomplished by a SecurityTetraplet, which is data structure with four data fields:
struct SecurityTetraplet:
peer_id: string
service_id: string
fn_name: string
getter: string
SecurityTetraplets are provided with the function call arguments for each (service) function call and are checked by the called service. Hence, authentication based on the (service caller id == service owner id) relation can be established at service ingress and leveraged to build powerful, fine-grained identity and access management solutions enabling true zero trust architectures.
Trust Layer
The Fluence protocol offers an alternative to node selection, i.e. connection and permissioning, approaches, such as Kademlia, called TrustGraph. A TrustGraph is comprised of subjectively weights assigned to nodes to manage peer connections. TrustGraphs are node operator specific and transitive. That is, a trusted node's trusted neighbors are considered trustworthy.
{% hint style="info" %} TrustGraph is currently under active development. Please check the repo for progress. {% endhint %}
Application
An application is the "frontend" to one or more services and their execution sequence. Applications are developed by coordinating one or more services into a logical compute unit and tend to live outside the Fluence network**,** e.g., the browser as a peer-client. They can be executed in various runtime environments ranging from browsers to backend daemons.
Scaling Applications
As discussed previously, decoupling at the network and business logic levels is at the core of the Fluence protocol and provides the major entry points for scaling solutions.
At the peer-to-peer network level, scaling can be achieved with subnetworks. Subnetworks are currently under development and we will update this section in the near future.
At the service level, we can achieve scale through parallelization due to the decoupling of resource management from infrastructure. That is, sequential and parallel execution flow logic are an inherent part of Aqua's programming model. In order to be able to achieve concurrency, the target services need to be available on multiple peers as module calls are blocking.
Figure 8: Stylized Par Execution
