11 KiB
4. Service Composition And Reuse With Aqua
In the previous three sections, you got a taste of using Aqua with browsers and how to create and deploy a service. In this section, we discuss how to compose an application from multiple distributed services using Aqua. In Fluence, we don't use JSON-RPC or REST endpoints to address and execute the service, we use Aqua.
Recall, Aqua is a purpose-built distributed systems and peer-to-peer programming language that resolves (Peer Id, Service Id) tuples to facilitate service execution on the host node without developers having to worry about transport or network routing. And with Aqua VM available on each Fluence peer-to-peer node, Aqua allows developers to ergonomically locate and execute distributed services.
{% hint style="info" %} In case you haven't set up your development environment, follow the setup instructions and clone the examples repo:
git clone https://github.com/fluencelabs/examples
{% endhint %}
Composition With Aqua
A service is one or more linked WebAssembly (Wasm) modules that may be linked at runtime. Said dependencies are specified by a blueprint which is the basis for creating a unique service id after the deployment and initiation of the blueprint on our chosen host for deployment. See Figure 1.
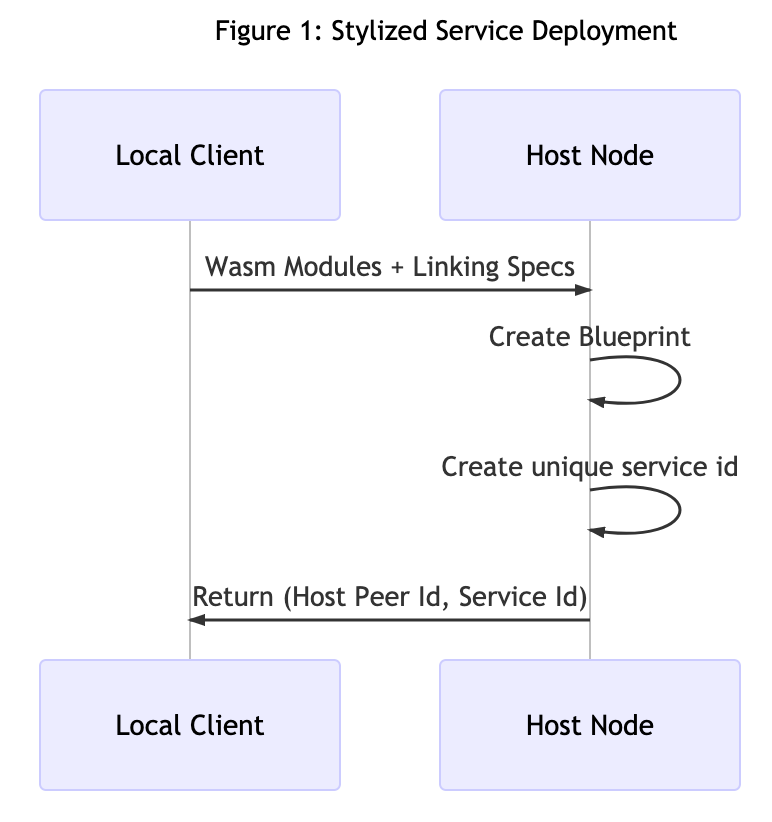
When we deploy our service, as demonstrated in section two, the service is "out there" on the network and we need a way to locate and execute the service if w want to utilize he service as part of our application.
Luckily, the (Peer Id, Service Id) tuple we obtain from the service deployment process contains all the information Aqua needs to locate and execute the specified service instance.
Let's create a Wasm module with a single function that adds one to an input in the adder directory:
#[marine]
fn add_one(input: u64) -> u64 {
input + 1
}
For our purposes, we deploy that module as a service to three hosts: Peer 1, Peer 2, and Peer 3. Use the instructions provided in section two to create the module and deploy the service to three peers of your choosing. See 4-composing-services-with-aqua/adder for the code and data/distributed_service.json for the (Peer Id, Service Id) tuples already deployed to three network peers.
Once we got the services deployed to their respective hosts, we can use Aqua to compose an admittedly simple application by composing the use of each service into an workflow where the (Peer Id, Service Id) tuples facilitate the routing to and execution of each service. Also, recall that in the Fluence peer-to-peer programming model the client need not, and for the most part should not, be involved in managing intermediate results. Instead, results are "forward chained" to the next service as specified in the Aqua workflow.
Using our add_one service and starting with an input parameter value of one, utilizing all three services, we expect a final result of four given sequential service execution:
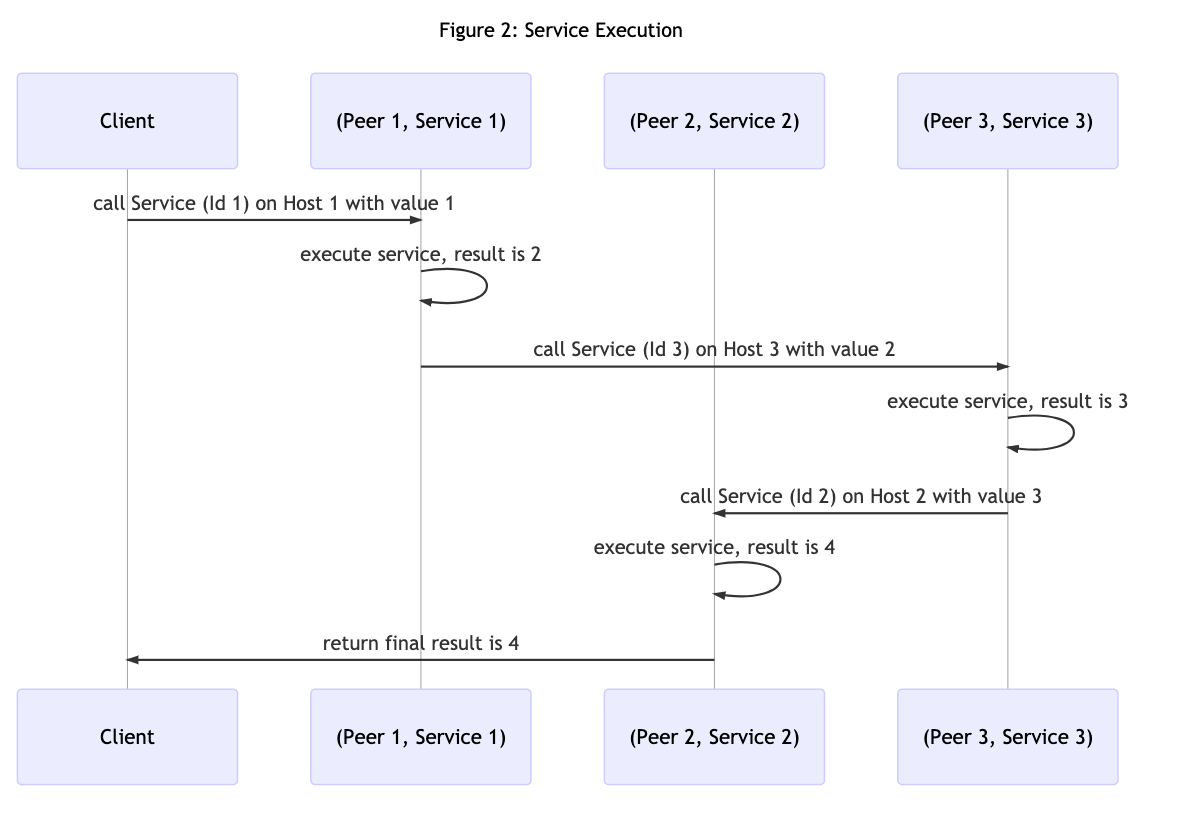
The underlying Aqua script may look something like this (see the aqua-script directory):
-- aqua-scripts/adder.aqua
-- service interface for Wasm module
service AddOne:
add_one: u64 -> u64
-- convenience struct for (Peer Id, Service Id) tuples
data NodeServiceTuple:
node_id: string
service_id: string
func add_one_three_times(value: u64, ns_tuples: []NodeServiceTuple) -> u64:
on ns_tuples!0.node_id:
AddOne ns_tuples!0.service_id
res1 <- AddOne.add_one(value)
on ns_tuples!1.node_id:
AddOne ns_tuples!1.service_id
res2 <- AddOne.add_one(res1)
on ns_tuples!2.node_id:
AddOne ns_tuples!2.service_id
res3 <- AddOne.add_one(res2)
<- res3
Let's give it a whirl! Using the already deployed services or your even better, your own deployed services, let's compile out Aqua script in the 4-composing-services-with-aqua directory. We use aqua run to execute the above Aqua script:
aqua run \
-i aqua-scripts \
-a /dns4/kras-04.fluence.dev/tcp/19001/wss/p2p/12D3KooWFEwNWcHqi9rtsmDhsYcDbRUCDXH84RC4FW6UfsFWaoHi \
-f 'add_one_three_times(5, arg)' \
-d '{"arg":[{
"node_id": "12D3KooWFtf3rfCDAfWwt6oLZYZbDfn9Vn7bv7g6QjjQxUUEFVBt",
"service_id": "7b2ab89f-0897-4537-b726-8120b405074d"
},
{
"node_id": "12D3KooWKnEqMfYo9zvfHmqTLpLdiHXPe4SVqUWcWHDJdFGrSmcA",
"service_id": "e013f18a-200f-4249-8303-d42d10d3ce46"
},
{
"node_id": "12D3KooWFEwNWcHqi9rtsmDhsYcDbRUCDXH84RC4FW6UfsFWaoHi",
"service_id": "dbaca771-f0a6-4d1e-9af7-5b49368ffa9e"
}]
}'
Since we are starting with a value of 5 and increment it three times, we expect an 8 which we get:
Your peerId: 12D3KooWHgS2T8mWoAkxoEaLtPjHauai2mVPrNSLDKZVd71KoxS1
8
Of course, we can drastically change our application logic by changing the execution flow of our workflow composition. In the above example, we executed each of the three services once in sequence. Alternatively, we could also execute them in parallel or some combination of sequential and parallel execution arms.
Reusing our deployed services with a different execution flow may look like the following:
```aqua
-- service interface for Wasm module
service AddOne:
add_one: u64 -> u64
-- convenience struc for (Peer Id, Service Id) tuples
data NodeServiceTuple:
node_id: string
service_id: string
-- our app as defined by the worflow expressed in Aqua
func add_one_par(value: u64, ns_tuples: []NodeServiceTuple) -> []u64:
res: *u64
for ns <- ns_tuples par:
on ns.node_id:
AddOne ns.service_id
res <- AddOne.add_one(value)
Op.noop()
join res[2] --< flatten the stream variable
<- res --< return the final results [value +1, value + 1, value + 1, ...] to the client
Unlike the sequential execution model, this example returns an array where each item is the incremented value, which is captured by the stream variable res. That is, for a starting value of five (5), we obtain [6,6,6] assuming our NodeServiceTuple array provided the three distinct (Peer Id, Service Id) tuples.
Running the script with aqua:
aqua run \
-i aqua-scripts \
-a /dns4/kras-04.fluence.dev/tcp/19001/wss/p2p/12D3KooWFEwNWcHqi9rtsmDhsYcDbRUCDXH84RC4FW6UfsFWaoHi \
-f 'add_one_par(5, arg)' \
-d '{"arg":[{
"node_id": "12D3KooWFtf3rfCDAfWwt6oLZYZbDfn9Vn7bv7g6QjjQxUUEFVBt",
"service_id": "7b2ab89f-0897-4537-b726-8120b405074d"
},
{
"node_id": "12D3KooWKnEqMfYo9zvfHmqTLpLdiHXPe4SVqUWcWHDJdFGrSmcA",
"service_id": "e013f18a-200f-4249-8303-d42d10d3ce46"
},
{
"node_id": "12D3KooWFEwNWcHqi9rtsmDhsYcDbRUCDXH84RC4FW6UfsFWaoHi",
"service_id": "dbaca771-f0a6-4d1e-9af7-5b49368ffa9e"
}]
}'
We get the expected result:
Your peerId: 12D3KooWB4eHpj2VfPDW9hJ5uMQiccV27uSJyHWiMUGN2hqkefV8
waiting for an argument with idx '2' on stream with size '0'
waiting for an argument with idx '2' on stream with size '0'
waiting for an argument with idx '2' on stream with size '1'
waiting for an argument with idx '2' on stream with size '1'
[
6,
6,
6
]
We can improve on our business logic and change our input arguments to make parallelization a little more useful. Let's extend our data struct and update the workflow:
-- aqua-scripts/adder.aqua
data ValueNodeService:
node_id: string
service_id: string
value: u64 --< add value
func add_one_par_alt(payload: []ValueNodeService) -> []u64:
res: *u64
for vns <- payload par: --< parallelized run
on vns.node_id:
AddOne vns.service_id
res <- AddOne.add_one(vns.value)
Op.noop()
join res[2]
<- res
And we can run the aqua run command:
aqua run \
-i aqua-scripts \
-a /dns4/kras-04.fluence.dev/tcp/19001/wss/p2p/12D3KooWFEwNWcHqi9rtsmDhsYcDbRUCDXH84RC4FW6UfsFWaoHi \
-f 'add_one_par_alt(arg)' \
-d '{"arg":[{
"value": 5,
"node_id": "12D3KooWFtf3rfCDAfWwt6oLZYZbDfn9Vn7bv7g6QjjQxUUEFVBt",
"service_id": "7b2ab89f-0897-4537-b726-8120b405074d"
},
{
"value": 10,
"node_id": "12D3KooWKnEqMfYo9zvfHmqTLpLdiHXPe4SVqUWcWHDJdFGrSmcA",
"service_id": "e013f18a-200f-4249-8303-d42d10d3ce46"
},
{
"value": 15,
"node_id": "12D3KooWFEwNWcHqi9rtsmDhsYcDbRUCDXH84RC4FW6UfsFWaoHi",
"service_id": "dbaca771-f0a6-4d1e-9af7-5b49368ffa9e"
}]
}'
Given our input values [5, 10, 15], we get the expected output array of [6, 11, 16]:
Your peerId: 12D3KooWNHJkYtevGk5ccZFyHyfinTJYNDJZ4C9KN9cJGEqaWVe9
waiting for an argument with idx '2' on stream with size '0'
waiting for an argument with idx '2' on stream with size '0'
waiting for an argument with idx '2' on stream with size '1'
waiting for an argument with idx '2' on stream with size '1'
[
6,
11,
16
]
Alternatively, we can run our Aqua scripts with a Typescript client. In the client-peer directory:
npm i
npm start
Which of course gives us the expected results:
created a Fluence client 12D3KooWGve35kvMQ8USbmtRoMCzxaBPXSbqsZxfo6T8gBAV6bzy with relay 12D3KooWKnEqMfYo9zvfHmqTLpLdiHXPe4SVqUWcWHDJdFGrSmcA
add_one to 5 equals 6
add_one sequentially equals 8
add_one parallel equals [ 6, 6, 6 ]
add_one parallel alt equals [ 11, 6, 16 ] --< order may differ for you
Summary
This section illustrates how Aqua allows developers to locate and execute distributed services on by merely providing a (Peer Id, Service Id) tuple and the associated data. From an Aqua user perspective, there are no JSON-RPC or REST endpoints just topology tuples that are resolved on peers of the network. Moreover, we saw how the Fluence peer-to-peer workflow model facilitates a different request-response model than commonly encountered in traditional client-server applications. That is, instead of returning each service result to the client, Aqua allows us to forward the (intermittent) result to the next service, peer-to-peer style.
Furthermore, we explored how different Aqua execution flows, e.g. sequential vs. parallel, and data models allow developers to compose drastically different workflows and application re-using already deployed services. For more information on Aqua, please see the Aqua book and for more information on Fluence development, see the developer docs.